
660
shares
聚米幫你連接全球客戶
服務熱(rè)線:400-8817-968

發布于:2019-10-14

Googlebot僅遵循特定的(de)命令,忽略表格和(hé)cookie,僅對(duì)正确編碼的(de)鏈接進行爬網。因此,站點建設中的(de)錯誤和(hé)疏忽會影(yǐng)響對(duì)其進行爬網和(hé)建立索引的(de)能力。
很自然地假設搜索引擎可(kě)以訪問人(rén)們在網站上看到的(de)所有内容。但是事實并非如此。
據報道,Googlebot可(kě)以填寫表格,接受Cookie并抓取所有類型的(de)鏈接。但是訪問這(zhè)些元素将消耗看似無限的(de)爬網和(hé)索引資源。
因此,Googlebot僅遵循某些命令,忽略表單和(hé)cookie,僅爬網使用(yòng)适當的(de)anchor标簽和(hé)href編碼的(de)鏈接。
以下(xià)是阻止Googlebot和(hé)其他(tā)搜索引擎機器人(rén)抓取(和(hé)編制索引)您所有網頁的(de)七個(gè)項目。
1.基于位置的(de)頁面
具有支持區(qū)域設置的(de)頁面的(de)站點會檢測訪問者的(de)IP地址,然後根據該位置顯示内容。但這(zhè)不是萬無一失的(de)。比如:訪客的(de)IP似乎在波士頓,即使她住在紐約也(yě)是如此。因此,她會收到她不想要的(de)有關波士頓的(de)内容。
Googlebot的(de)默認IP來(lái)自加利福尼亞州聖何塞地區(qū)。因此,Googlebot僅會看到與該地區(qū)相關的(de)内容。
首次進入站點時(shí)基于位置的(de)内容很好。但是後續内容應基于單擊的(de)鏈接,而不是IP地址。
有機搜尋成功的(de)無形障礙是最難發現的(de)障礙之一。
2.基于Cookie的(de)内容
網站将cookie放置在Web浏覽器上,以個(gè)性化(huà)訪問者的(de)體驗,例如語言首選項或渲染面包屑的(de)單擊路徑。訪問者隻能通(tōng)過Cookie,而不是單擊鏈接來(lái)訪問的(de)内容将無法被搜索引擎機器人(rén)訪問。
例如,某些站點基于cookie提供國家和(hé)語言内容。如果您訪問在線商店(diàn)并選擇以法語閱讀,則會設置一個(gè)cookie,而您在網站上的(de)其餘訪問都将以法語進行。URL與網站使用(yòng)英語時(shí)的(de)URL相同,但是内容不同。
網站所有者大(dà)概希望法語内容在自然搜索中排名,以将講法語的(de)人(rén)帶到該網站。但是不會。如果URL不會随著(zhe)内容的(de)更改而改變,那麽搜索引擎将無法抓取或排名其他(tā)版本。
3.不可(kě)抓取的(de)JavaScript鏈接
對(duì)于Google來(lái)說,鏈接不是鏈接,除非它同時(shí)包含錨标記和(hé)指向特定URL 的(de)href。錨文本也(yě)是可(kě)取的(de),因爲它可(kě)以确定鏈接到的(de)頁面的(de)相關性。
下(xià)面的(de)假設标記著(zhe)重說明(míng)了(le)可(kě)抓取鏈接和(hé)不可(kě)抓取鏈接與Googlebot的(de)區(qū)别:“将被抓取”與“不被抓取”。
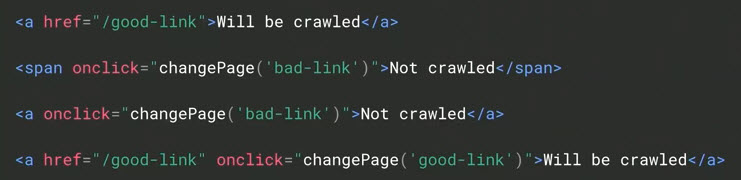
Google要求鏈接同時(shí)包含錨标記和(hé)指向特定URL 的(de)href。在此示例中,Googlebot将抓取第一行和(hé)第四行。但是它不會爬第二和(hé)第三。
電子商務網站傾向于使用(yòng)onclick(指向其他(tā)頁面的(de)鼠标懸停下(xià)拉菜單)而不是錨标記來(lái)編碼其鏈接。雖然這(zhè)種方法适用(yòng)于人(rén)類,但Googlebot不會将其識别爲可(kě)抓取的(de)鏈接。因此,以這(zhè)種方式鏈接的(de)頁面可(kě)能存在索引問題。
4.标簽網址
AJAX是一種JavaScript形式,可(kě)以刷新内容而無需重新加載頁面。刷新後的(de)内容會在頁面的(de)URL中插入井号(井号:#)。不幸的(de)是,#标簽并不總是在以後的(de)訪問中複制預期的(de)内容。如果搜索引擎将主題标簽URL編入索引,則内容可(kě)能不是搜索者正在尋找的(de)内容。
雖然大(dà)多(duō)數搜索引擎優化(huà)人(rén)員(yuán)都了(le)解标簽标簽URL固有的(de)索引問題,但營銷人(rén)員(yuán)通(tōng)常會驚訝地發現其URL結構的(de)這(zhè)一基本要素正在引起自然搜索麻煩。
5. Robots.txt 不允許
robots.txt文件是網站根目錄下(xià)的(de)原始文本文檔。它告訴機器人(rén)(選擇服從)通(tōng)常通(tōng)過disallow命令來(lái)爬網哪些内容。
Disallow命令不會阻止建立索引。但是由于機器人(rén)無法确定頁面的(de)相關性,它們可(kě)以阻止頁面排名。
禁止命令可(kě)能會意外出現在robots.txt文件中(例如,重新設計實時(shí)發布時(shí)),從而阻止搜索機器人(rén)抓取整個(gè)網站。robots.txt文件中存在禁止對(duì)象是檢查自然搜索流量突然下(xià)降的(de)第一件事。
6. Meta Robots Noindex
URL的(de)meta标簽的(de)noindex屬性指示搜索引擎機器人(rén)不要對(duì)該頁面進行索引。它是逐頁應用(yòng)的(de),而不是用(yòng)于管理(lǐ)整個(gè)站點的(de)單個(gè)文件,例如disallow命令。
但是,noindex屬性比禁止索引更強大(dà),因爲它們會停止索引。
像禁止命令一樣,noindex屬性可(kě)能會意外地實時(shí)上線。它們是最難發現的(de)阻止者之一。
7.不正确的(de)規範标簽
規範标簽可(kě)識别要從多(duō)個(gè)相同版本中索引的(de)頁面。規範标簽是防止重複内容的(de)重要武器。所有非規範頁面将其鏈接權限(鏈接到它們的(de)頁面傳達的(de)值)歸因于規範URL。非規範頁面未編制索引。
規範标簽隐藏在源代碼中。錯誤可(kě)能很難發現。如果您網站上的(de)所需網頁未編入索引,則可(kě)能是錯誤的(de)規範标簽。
評論展示
660
shares
掃碼加微信咨詢

15815846676
長(cháng)按号碼加微信
在線留言





參與評論